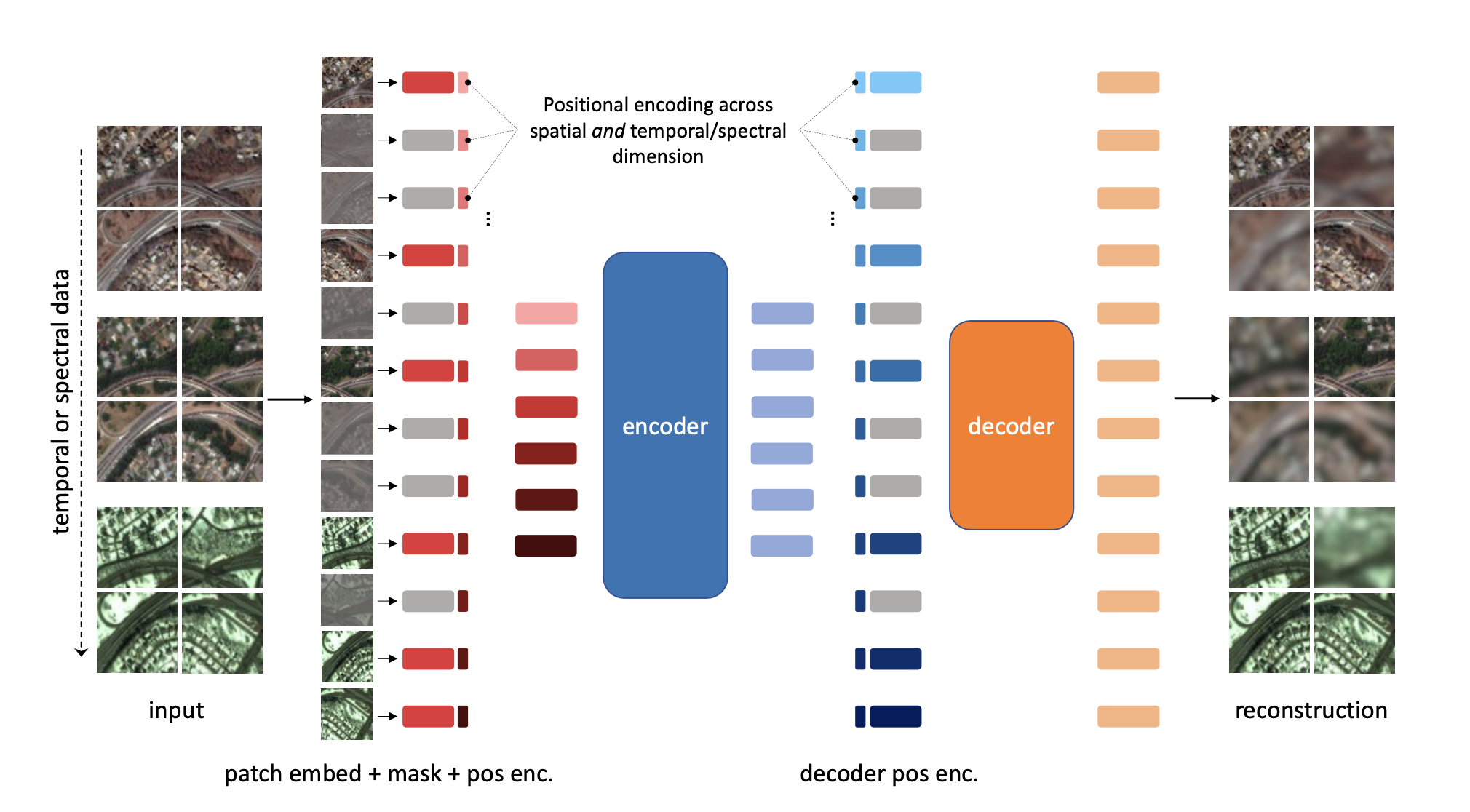
Unsupervised pre-training methods for large vision models have shown to enhance performance on downstream supervised tasks. Developing similar techniques for satellite imagery presents significant opportunities as unlabelled data is plentiful and the inherent temporal and multi-spectral structure provides avenues to further improve existing pre-training strategies. In this paper, we present SatMAE, a pre-training framework for temporal or multi-spectral satellite imagery based on Masked Autoencoder (MAE). To leverage temporal information, we include a temporal embedding along with independently masking image patches across time. In addition, we demonstrate that encoding multi-spectral data as groups of bands with distinct spectral positional encodings is beneficial. Our approach yields strong improvements over previous state-of-the-art techniques, both in terms of supervised learning performance on benchmark datasets (up to 7%), and transfer learning performance on downstream remote sensing tasks, including land cover classification (up to 14%) and semantic segmentation.
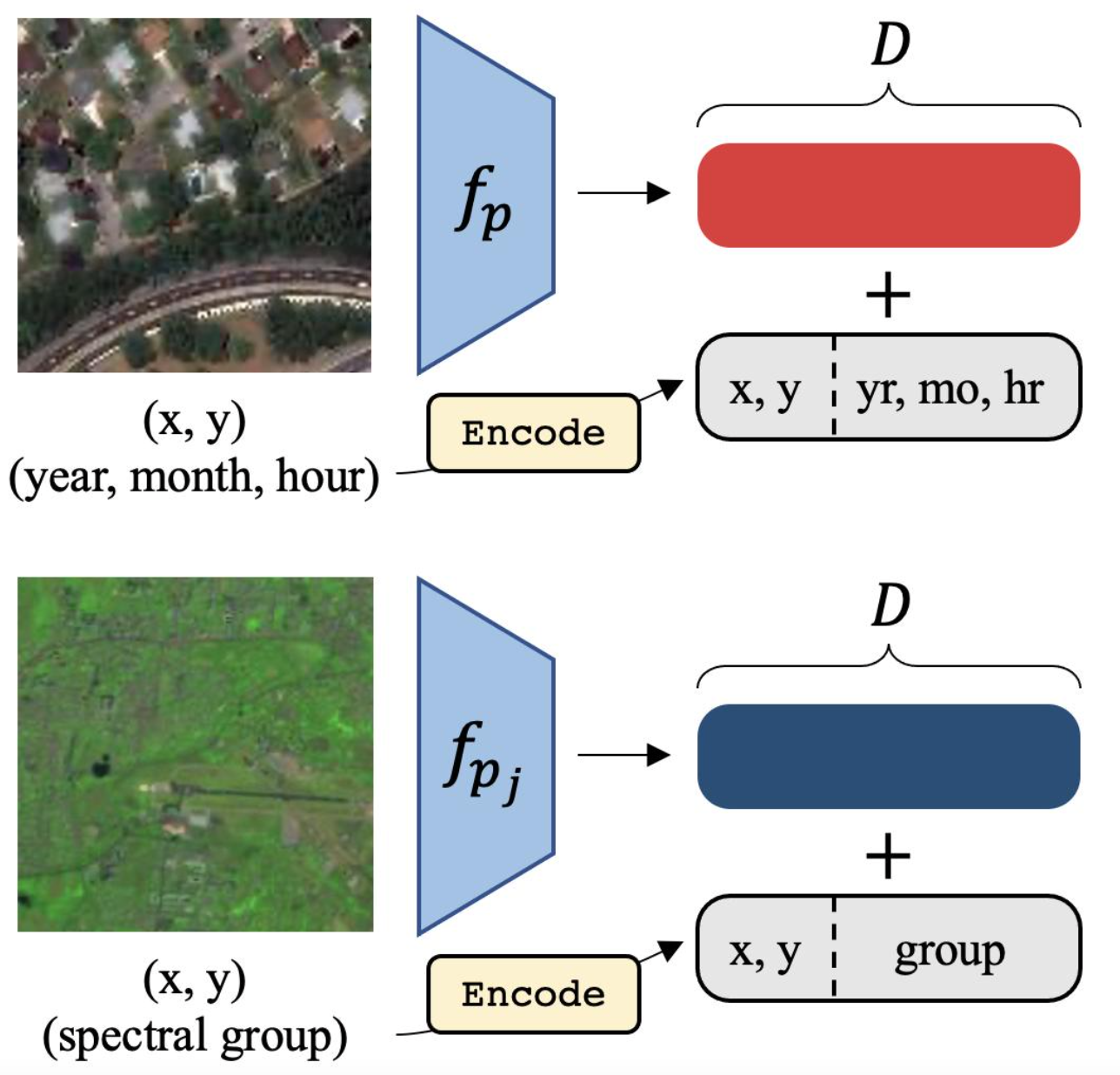
We introduce a Temporal SatMAE and a Spectral SatMAE to handle temporal and multi-spectral satellite data. In addition to encoding the spatial position of patches, we also encode temporal and spectral information within the positional embedding. While each image in the temporal/spectral sequence is "patchified" separately, we investigate two masking strategies:
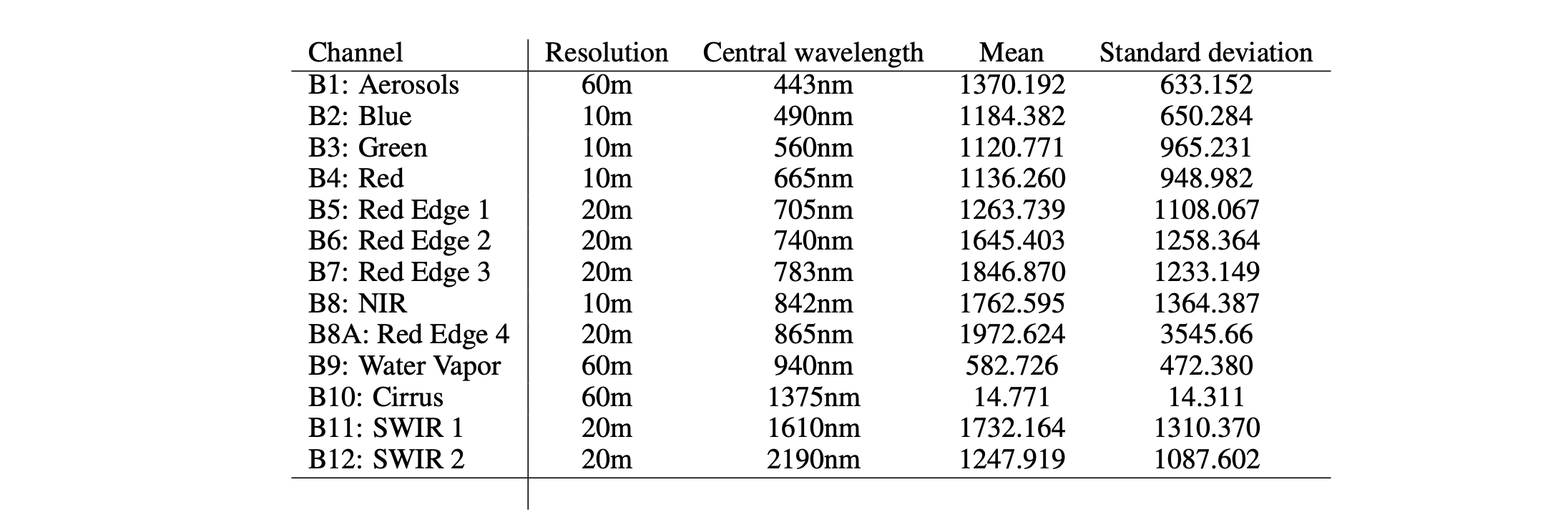
 Below is the table of mean and standard deviation of pixel values for each channel across the fMoW Sentinel training dataset.
Note that channel B10 does not contain bottom-of-atmosphere information, and is no longer accessible on Google Earth Engine.
Further details can be found here.
Below is the table of mean and standard deviation of pixel values for each channel across the fMoW Sentinel training dataset.
Note that channel B10 does not contain bottom-of-atmosphere information, and is no longer accessible on Google Earth Engine.
Further details can be found here.
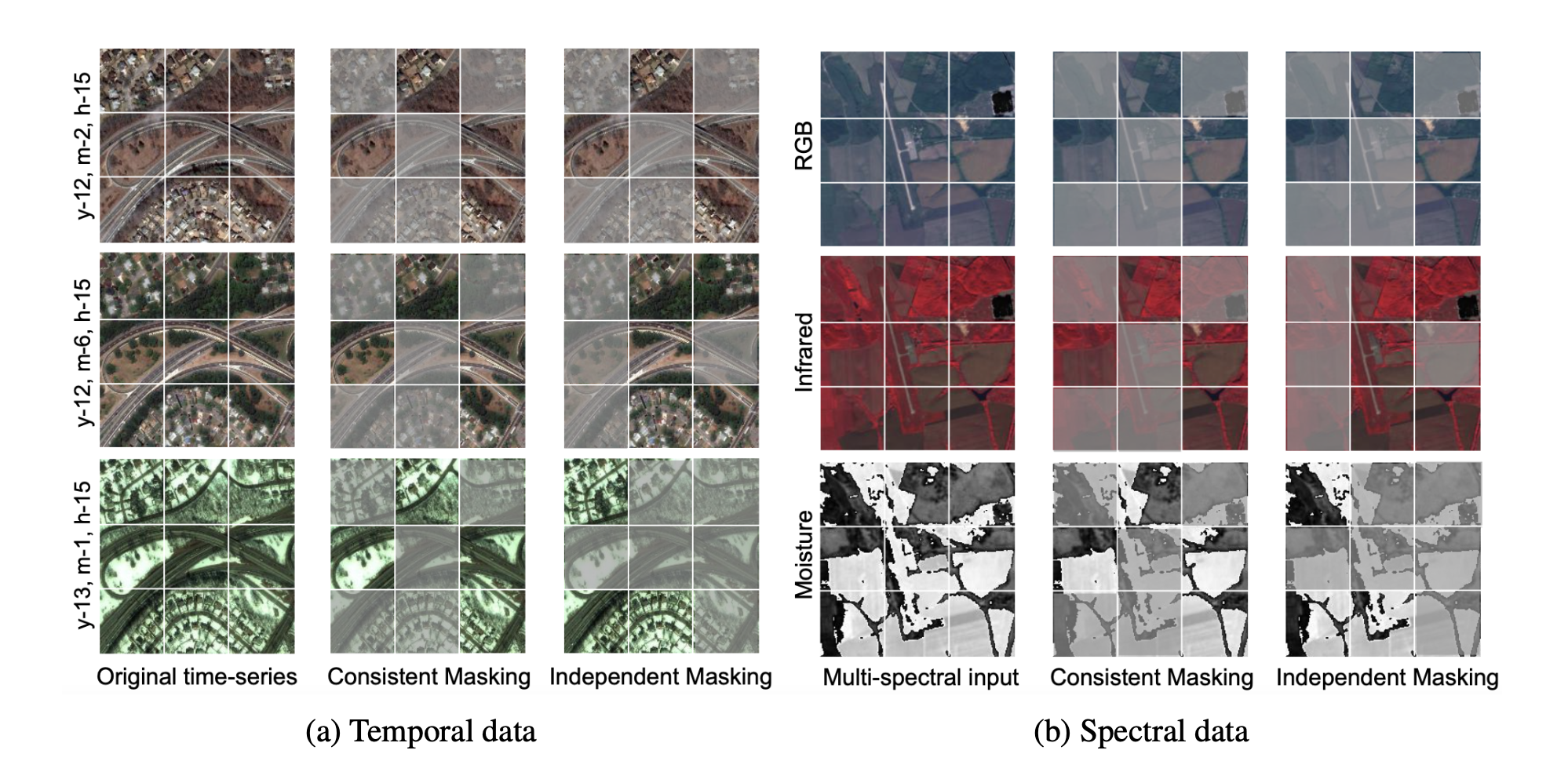
 Visualizations of SatMAE in-painting under different settings. RGB represents bands B4, B3, B2,
from group B2, B3, B4, B8. NIR represents bands B7, B6, B5, from group B5, B6, B7, B8A. SWIR represents
bands B11 in grayscale, from group B11, B12. For each method, we show the input band group masked and
reconstructed side-by-side. We note that the reconstruction for visible patches is worse than for the masked
patches, since no loss is computed on visible patches. The top-left quadrant represents a multi-spectral image of
an airport, the top-right quadrants is of a recreational facility, the bottom-left is of an airport and the bottom-right
is of an amusement park. We can see a clear improvement in the quality of reconstruction under SatMAE+Group+IM compared
to SatMAE+Group+CM and SatMAE+Stack. Independent masking results in sharper reconstructions,
whereas the results from consistent masking and stacking the channels are much fuzzier.
Visualizations of SatMAE in-painting under different settings. RGB represents bands B4, B3, B2,
from group B2, B3, B4, B8. NIR represents bands B7, B6, B5, from group B5, B6, B7, B8A. SWIR represents
bands B11 in grayscale, from group B11, B12. For each method, we show the input band group masked and
reconstructed side-by-side. We note that the reconstruction for visible patches is worse than for the masked
patches, since no loss is computed on visible patches. The top-left quadrant represents a multi-spectral image of
an airport, the top-right quadrants is of a recreational facility, the bottom-left is of an airport and the bottom-right
is of an amusement park. We can see a clear improvement in the quality of reconstruction under SatMAE+Group+IM compared
to SatMAE+Group+CM and SatMAE+Stack. Independent masking results in sharper reconstructions,
whereas the results from consistent masking and stacking the channels are much fuzzier.


@inproceedings{
satmae2022,
title={Sat{MAE}: Pre-training Transformers for Temporal and Multi-Spectral Satellite Imagery},
author={Yezhen Cong and Samar Khanna and Chenlin Meng and Patrick Liu and Erik Rozi and Yutong He and Marshall Burke and David B. Lobell and Stefano Ermon},
booktitle={Advances in Neural Information Processing Systems},
editor={Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho},
year={2022},
url={https://openreview.net/forum?id=WBhqzpF6KYH}
}